
Im 9. Teil der Einführung in das Netz der Netze, beschäftigen wir uns mit dem Hypertext Transfer Protocol. Es wird kurz HTTP genannt und nutzt indirekt die Dienste des Internet Protocols (IP) und baut direkt auf dem Transmission Control Protocol (TCP) auf.
Auch wenn es dir vielleicht nicht direkt auffällt, aber du kommst fast täglich mit dem Protokoll in Berührung. Es spielt nämlich die zentrale Rolle bei der Auslieferung von Webseiten im Internet.
Wenn du dich also mit der Erstellung deiner eigenen Website beschäftigst oder die im Hintergrund ablaufenden Prozesse bei der Auslieferung einer einzelnen Webseite besser verstehen möchtest, dann ist dieser Artikel besonders interessant für dich. Ja fast schon Pflichtlektüre!
Dieser Artikel ist Teil des 21.-teiligen Kurses “Das Internet“.
Einführung in das Hypertext Transfer Protocol
Beim Hypertext Transfer Protocol handelt es sich um ein zustandsloses Protokoll, welches zur Übertragung von Daten in einem Rechnernetz genutzt wird. Wie eingangs bereits erwähnt, wird es hauptsächlich zur Darstellung von Webseiten aus dem World Wide Web in einem Browser verwendet.
Das Hypertext Transfer Protocol ist aber nicht nur auf diese Aufgabe beschränkt. Mittlerweile wird es auch als allgemeines Datenübertragungsprotokoll eingesetzt. So sorgen Erweiterungen wie WebDAV zum Beispiel dafür, dass mittels HTTP ganze Ordner übertragen werden können.
HTTP ist leider nicht in der Lage, Zustände zu speichern. Deshalb auch zustandsloses Protokoll.
Das bedeutet, dass jede Anfrage als neue Transaktion behandelt wird, selbst wenn die Anfrage vom gleichen Nutzer stammt. Somit ist es ohne besondere Vorkehrungen leider nicht möglich, Sitzungen zu definieren, wie sie z.B. bei Warenkörben in einem Onlineshop oder bei Passwort geschützten Webanwendungen erforderlich sind.
Seit der ersten veröffentlichten Version des Hypertext Transfer Protocol, hat sich trotzdem einiges getan. So ist es z.B. nicht mehr notwendig, dass für jede HTTP-Anfrage eine neue TCP-Verbindung aufgebaut werden muss. Die aktuelle Version 1.1 setzt auf persistente Verbindungen, die nicht beendet werden, wenn eine Antwort vom Webserver gesendet worden ist.
Dies hat den großen Vorteil, dass der Webserver alle Elemente einer Website innerhalb derselben TCP-Verbindung übertragen kann und nicht mehr ständig mit dem Auf- und Abbau von Verbindungen beschäftigt ist. Das spart Zeit und wirkt sich positiv auf die Website Performance aus.
Weiterhin werden bei der neuen Version Techniken eingesetzt, um hierarchische Proxys, virtuelle Hosts und Caching-Mechanismen zu unterstützen. Auf einzelne Caching-Mechanismen, gehe ich später in diesem Artikel noch ein.
Wie funktioniert HTTP?
Beim Hypertext Transfer Protocol findet die Kommunikation nach dem Client-Server-Modell statt. Hier werden Aufgaben und Dienstleistungen auf verschiedene Stellen im Netzwerk verteilt. Standardmäßig unterscheiden wir zwei verschiedene Stellen: Einmal den Client und auf der anderen Seite den Server.
Der Client kann auf Wunsch eine Dienstleistung vom Server in Anspruch nehmen, indem er eine Anfrage an diesen stellt. Der Server, welcher sich auf dem gleichen oder einem entfernten Rechner im Netzwerk befindet, beantwortet diese Anfrage.
Nach diesem Prinzip funktioniert auch die Kommunikation bei HTTP.
Eine Anfrage wird von deinem Browser (HTTP-Client) an einen Webserver (HTTP-Server) gesendet. Der Webserver bearbeitet die Anfrage vom Browser und schickt eine Antwort zurück. Sollte innerhalb einer festgelegten Zeit (Timeout) keine weitere Anfrage vom Client an den Server gestellt werden, wird die Verbindung beendet.
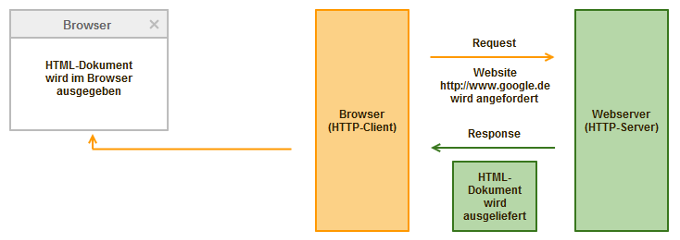
Schematische Darstellung der Funktionsweise des Hypertext Transfer Protocols
Die Funktionsweise ist natürlich sehr vereinfacht dargestellt, aber fürs Erste soll das reichen. Wichtig ist an dieser Stelle noch zu wissen, dass die Anfrage vom Client auch Request und die Antwort vom Server Response genannt wird.
Die einzelnen Request- und Response-Meldungen werden im Text-Format über das Transmission Control Protocol verschickt. Sie bestehen aus einem Header und den Daten. Die Daten enthalten hierbei das angeforderte HTML-Dokument oder Eingaben eines Benutzers, die vom Client an den Webserver verschickt werden.
Der Header hingegen, enthält die Steuerinformationen. Diese bestehen aus verschiedenen Feldern und bei einem Request werden andere Felder genutzt als bei einem Response. Insgesamt existieren ungefähr 60 verschiedene Felder.
Wenn du dir einen Überblick über die Felder des Headers verschaffen möchtest, dann schau dir am besten die Liste der HTTP-Headerfelder genauer an. Einzelne Felder schauen wir uns aber auch zusammen in den Abschnitten Anfrage, Antwort und HTTP-Caching an.
Vorher möchte ich dir aber zeigen, wie die Adressierung beim Hypertext Transfer Protocol funktioniert.
Adressierung
Im vorherigen Abschnitt habe ich dir das Client-Server-Modell erklärt, welches bei HTTP zur Kommunikation eingesetzt wird. Bei diesem schickt der Client einen Request an den Webserver und erhält eine Antwort (Response). Doch woher weiß der Server, welche Datei oder welches HTML-Dokument er als Antwort zurückschicken soll?
Genau dafür gibt es die sogenannte URL, die der Client bei seiner Anfrage an den Server übermitteln muss.
URL ist die Abkürzung für Uniform Resource Locator und erst mit der Einführung von URL’s wurde es möglich, die verschiedenen Ressourcen im Internet mit einer einheitlichen Syntax anzusprechen und damit verfügbar zu machen.
Aufgebaut ist eine URL wie folgt:
http://serverbezeichnung.domainname.top-level-domain:tcp-port/pfad/datei
Für meinen Blog würde eine typische URL ungefähr so aussehen:
https://www.webschmoeker.de:80/grundlagen/http-hypertext-transfer-protocol/
Hier besteht die URL aus der Angabe des Transport-Protokolls und wie sollte es auch anders sein, ist dies in unserem Beispiel http://. Danach folgt die Serverbezeichnung www, welche optional ist. Darauf schließt der Domainname (webschmoeker) und die Top-Level-Domain (.de) an.
Die Angabe des Ports, erlaubt die Ansteuerung des angegebenen TCP-Ports. In unserem Beispiel ist dies der Port 80, welcher der Standard-Port des Hypertext Transfer Protocols ist. Soll bei einer Anfrage der Standard-Port verwendet werden, kann dieser in der URL auch weggelassen werden. In einem solchen Fall, wird automatisch der Standard-Port des Transport-Protokolls verwendet.
Wenn die URL bis hier interpretiert worden ist, befinden wir uns bereits auf dem richtigen Webserver. Jetzt fehlt aber noch die Angabe des Ortes, an welchem der Webserver nach der abzurufende Ressource suchen soll. Deshalb folgt auf die Angabe des Ports, der eigentliche Pfad und der Dateiname.
Die Kombination aus Pfad und Dateiname ist der Teil der URL, der beim HTTP-Request angegeben werden muss. An welcher Stelle, dass erkläre ich dir im nächsten Abschnitt.
Die Anfrage
Die Anfrage oder auch HTTP-Request genannt, wird vom Client an den Server verschickt. Diese besteht aus einer dreiteiligen Anforderung, den eigentlichen Steuerinformationen des Headers und die bei einer Anfrage optionalen Daten.
Hier ein Beispiel ohne die optionalen Daten:
GET /grundlagen/das-internet/ HTTP/1.1
Host: www.webschmoeker.de
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:39.0) Gecko/20100101 Firefox/39.0 PTST/228
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
In der ersten Zeile (der Anforderung) unserer Anfrage, wird an erster Stelle die Request-Methode angegeben. Du siehst, dass es sich bei uns um die GET-Methode handelt. Sie wird zur Anforderung von HTML-Dateien oder anderen Quellen verwendet.
Im 2. Teil der Anforderung, wird der Pfad zur abzurufenden Ressource an das Hypertext Transfer Protocol übertragen. Der letzte Teil gibt die HTTP-Version an.
Auf die Anforderung folgen die einzelnen HTTP-Headerfelder. So findest du in Zeile 2 das Headerfeld “Host”. Dieses enthält den Domainnamen des Servers und ist zwingend erforderlich.
Wenn du nun den Wert des Feldes “Host” mit der Pfadangabe der Anforderung verbindest, würdest du die URL erhalten die ich abgefragt habe 😉
Auf das Feld “Host”, folgt das Feld “User-Agent”. In diesem stehen Informationen über den Browser, der die Anfrage gestellt hat. Mit Hilfe dieses Feldes wäre es also möglich, verschiedene Inhalte einer Website für verschiedene Browser auszuliefern.
Im Feld “Accept” werden die Inhaltstypen aufgelistet, die der Browser verarbeiten kann und in den Feldern “Accept-Language” sowie “Accept-Encoding”, folgen die akzeptierte Sprache und die unterstützten komprimierten Dateiformate.
Über das letzte Feld “Connection”, wird dem Server mitgeteilt, dass er die Verbindung nach seiner Antwort aufrechterhalten soll.
Nachdem Header, können durch eine Leerzeile getrennt, die vom Browser übermittelten Daten folgen. Dies können z.B. Daten aus einem Formular sein, welches du auf einer Website ausgefüllt und abgeschickt hast.
Die Antwort
Die Anfrage des Browsers wird mit einem HTTP-Response vom Webserver beantwortet. Dieser besteht aus einer dreiteiligen Status-Line, den Header-Informationen und den angefragten Daten (z.B. eine HTML-Datei).
Hier der Response auf unseren obigen Request:
HTTP/1.1 200 OK
Date: Wed, 29 Jul 2015 15:40:23 GMT
Server: Apache
X-Powered-By: PHP/5.4.42-nmm1
Vary: Accept-Encoding,Cookie
Cache-Control: max-age=3, must-revalidate, max-age=21600
WP-Super-Cache: Served supercache file from PHP
Content-Encoding: gzip
Content-Length: 11519
Expires: Wed, 29 Jul 2015 21:40:23 GMT
Connection: close
Content-Type: text/html; charset=UTF-8
In Zeile 1 siehst du sehr schön die dreiteilige Status-Line. Hier wird zuerst die verwendete HTTP-Version angegeben. Diese sollte natürlich mit der aus dem Request übereinstimmen, ansonsten könnten Client und Server nicht miteinander kommunizieren.
Auf die HTTP-Version folgt der Statuscode und eine kurze Mitteilung der Bedeutung des Statuscodes. Über diese Statuscodes oder Status-Meldungen, wird dem Client der Erfolg oder Misserfolg seiner Anfrage mitgeteilt. In unserem Beispiel konnte die Anfrage erfolgreich bearbeitet werden und dies teilt der Server dem Client über den Statuscode 200 mit. Der Statuscode 200 steht für OK, welches auch im Klartext in der Status-Line übertragen wird.
Zu den einzelnen Status-Meldungen kommen wir später noch einmal zurück, jetzt erst mal weiter mit der Auswertung des Response.
Auf die Status-Line schließen die Header-Informationen an. Die hier verwendeten Felder unterscheiden sich von denen des Requests und enthalten Informationen über den Webserver und den ausgelieferten Inhalt. Du siehst z.B. in Zeile 3, dass mein Blog auf einem Apache-Webserver läuft (Feld = Server) oder das die ausgelieferte HTML-Seite 11519 Bytes groß ist (Feld = Content-Length).
Auch wenn du es im obigen Beispiel nicht sehen kannst, folgen nach dem Header die Daten. Diese werden vom Header mit der Hilfe einer Leerzeile getrennt und es würde beispielsweise reiner HTML-Code innerhalb der Daten übertragen werden.
Das soll es dann auch erst mal zur Antwort des Servers gewesen sein. Was die anderen Felder des HTTP-Request bedeuten, kannst du dir ja aus der Liste der HTTP-Headerfelder heraussuchen. Ich möchte jetzt lieber die Zeit nutzen, um dir die bereits angesprochenen Request-Methoden und Status-Meldungen näher vorzustellen.
Die verschiedenen Request-Methoden
Bei der Anfrage des Clients bin ich bereits kurz auf die Request-Methode GET eingegangen. Dies ist aber nicht die einzige Methode, die der Client an den Server senden kann. Deshalb findest du hier eine Übersicht der Request-Methoden und wofür sie eingesetzt werden.
GET
Mit Hilfe der GET-Methode werden Ressourcen vom Server angefordert. Die angeforderte Ressource wird in der Anforderung der Anfrage über ihre URL eindeutig gekennzeichnet. Eine Ressource kann z.B. eine HTML-Seite oder ein Bild sein.
POST
Über diese Methode können Daten an den Server übertragen werden. Auch hier wird wieder eine URL angegeben, um die Daten an eine eindeutig identifizierbare Ressource zuschicken. Die Ressource ist nach der Übertragung dafür verantwortlich, die Daten zu verarbeiten.
Mögliche Anwendungsgebiete der POST-Methode:
- Übertragung von Formulardaten an einen datenverarbeitenden Prozess
- Übertragen einer Nachricht an eine Nachrichtengruppe oder Mailing-Liste
- Erweitern einer Datenbank durch eine Append-Operation
HEAD
HEAD führt zu demselben Ergebnis wie GET. Hier werden aber nur die Steuerinformationen übertragen und die eigentlichen Inhalte ausgespart. Durch die HEAD-Methode lässt sich somit sehr leicht die Existenz von Links überprüfen oder feststellen, ob Seiten immer noch auf dem Webserver existieren.
PUT
Die PUT-Methode ermöglicht es, eine neue Ressource auf dem Server anzulegen oder eine bereits bestehende zu modifizieren. Wo die neue Ressource angelegt wird oder sich die zu modifizierende Datei befindet, wird über die URL mitgeteilt.
DELETE
DELETE dient dem Löschen einer auf dem Webserver gespeicherten Ressource. Diese wird über die angegebene URL identifiziert.
CONNECT
Die Request-Methode CONNECT wird nur in Zusammenarbeit mit einem Proxy-Server implementiert, welcher in der Lage ist einen SSL-Tunnel zur Verfügung zu stellen.
OPTIONS
Mit dieser Methode kann eine Liste der vom Server unterstützen Request-Methoden abgefragt werden.
TRACE
Diese Methode wird hauptsächlich zu Test- oder Diagnosezwecken eingesetzt. Sie liefert die Anfrage des Clients so zurück, wie der Server sie empfangen hat. Damit kann überprüft werden, ob und wie die Anfrage auf dem Weg zum Server verändert worden ist.
Mit der Hilfe der hier vorgestellten Request-Methoden des Hypertext Transfer Protocols, lassen sich die unterschiedlichsten Webservices realisieren. So kannst du dir z.B. über die Verwendung der HEAD-Methode und einer Programmiersprache deiner Wahl einen Service erstellen, der deine Website automatisch nach defekten Links durchsucht.
Status-Meldungen
Als wir uns die Antwort des Servers auf die Anfrage eines Clients angeschaut haben, hatte ich die Status-Meldungen angesprochen. Sie werden immer in der Status-Line des HTTP-Response übertragen, um den Client über den Erfolg oder Misserfolg seiner Anfrage zu informieren.
Diese Status-Meldungen werden auch Statuscodes genannt und wir können sie in verschiedene Klassen einteilen:
| Klassen | Beschreibung der Klasse |
|---|---|
| 100-199 | Informationen |
| 200-299 | Meldungen über erfolgreiche Operationen |
| 300-399 | Diese deuten auf Umleitungen hin |
| 400-499 | Fehlermeldungen die vom Client ausgelöst werden |
| 500-599 | Fehlermeldungen die vom Server ausgelöst werden |
Über die wichtigsten HTTP-Statuscode habe ich bereits einen umfangreichen Artikel geschrieben und dazu eine Infografik erstellt. Klicke einfach auf den folgenden Link, um dich tierfer mit dem Thema der Status-Meldungen auseinanderzusetzen.
Die wichtigsten HTTP-Statuscodes
Besondere Techniken des Hypertext Transfer Protocols
In diesem Kapitel möchte ich dir 3 besondere Techniken von HTTP vorstellen. Techniken ist hier vielleicht nicht das richtige Wort, mir fiel aber kein geeigneteres ein. Ich hoffe du siehst mir diese kleine Ungenauigkeit nach oder teilst mir deinen Oberbegriff über die Kommentarfunktion mit 🙂
Wie auch immer. In diesem Kapitel möchte ich dir eine Einführung in das Caching in HTTP, die HTTP-Authentifizierung und die HTTP-Kompression geben.
Caching in HTTP
Das Hypertext Transfer Protocol stellt eine ganze Reihe von Mechanismen zur Verfügung, um das Caching von Webseiten möglichst gut zu unterstützen. Das Ziel dieser Caching-Mechanismen besteht darin, die Anzahl der Anfragen und die Zahl der vollständigen Antworten zu reduzieren.
Das erste Verfahren verringert die Anzahl der gesendeten Pakete im Netz. Dafür wird eine Technik eingesetzt, die auf Verfallszeiten beruht (Freshness über den Expires-Header).
Die Datenmenge der Antworten des Servers, wird beim zweiten Verfahren reduziert. Hier wird die Gültigkeit der angeforderten Einheit überprüft (Validierung) und somit die Zahl der Antworten reduziert, in denen Daten übermittelt werden müssen. Dadurch wird die Infrastruktur des Internets weniger stark belastet.
Caching über den Expires-Header
Wenn du eine Webseite das erste Mal abrufst, schickt der Webserver bei seiner Antwort, eine Verfallszeit (Expire-Date) über das Feld “Expires” mit. Rufst du die gleiche Webseite ein zweites Mal auf und dein Abruf liegt innerhalb dieser Verfallszeit, darf dein Browser die Seite aus seinem Browser-Cache laden. Dein Browser braucht also beim zweiten Abruf nicht mehr den Webserver zu kontaktieren.
Den Ablauf habe ich versucht schematisch darzustellen:
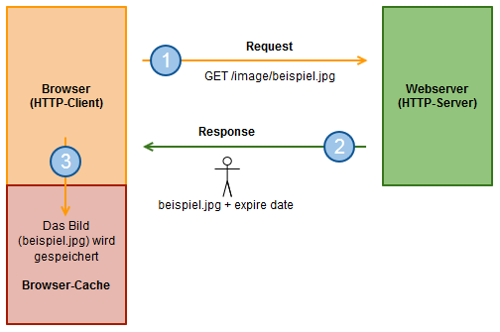
Expires-Header: 1. Anfrage vom Client
Bei der ersten Anfrage des Browser, wird die Datei beispiel.jpg beim Webserver angefordert (1). Der Webserver beantwortet die Anfrage und liefert das Bild aus. Zusätzlich wird über die Steuerinformationen das Expire-Date des Bildes mitgeliefert (2). Der Browser speichert das Bild, zusammen mit dem Expire-Date, in seinem lokalen Browser-Cache ab (3) und zeigt es danach an.
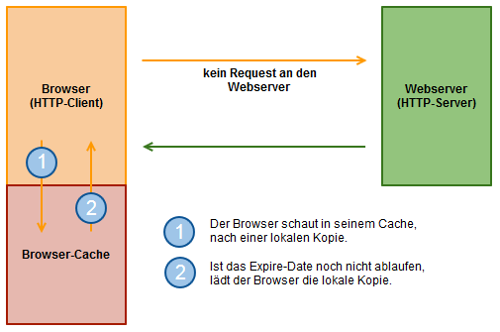
Expires-Header: 2. Anfrage des Bildes
Wenn du das gleiche Bild erneut abrufst, schaut der Browser zuerst in seinem Browser-Cache nach einer lokalen Kopie (1). Ist eine vorhanden und das Expire-Date noch nicht erreicht, lädt er die lokale Kopie (2) und spart sich die Anfrage beim Webserver.
Diesen Prozess kannst du auch sehr schön bei unserem Beispiel eines HTTP-Response nachvollziehen. Dort wird in Zeile 10 dem abrufenden Client mitgeteilt, dass die übermittelte Version der Webseite bis zum 29 Juli 2015 um 21:40:23 Uhr gültig ist.
Expires: Wed, 29 Jul 2015 21:40:23 GMT
Bis zu dieser Uhrzeit, dürfte mein Browser die Webseite aus seinem Browser-Cache laden. Erst nach Ablauf dieser Zeit, muss der Browser eine neue Anfrage an den Webserver stellen und nachfragen, ob sich das Dokument in der Zwischenzeit geändert hat (Caching-Mechanismus der Validierung).
Über den Expires-Header teilt der Webserver dem abzurufenden Client also mit, wie lange eine Repräsentation einer Webseite gültig ist. Je nach Webserver, kann dieser auf verschiedene Weise gesetzt werden. Üblicherweise enthält er aber die absolute Zeit bis zum Ablauf der Webseite. Es kann aber auch vorkommen, dass der Webserver keine explizite Verfallszeit übermittelt. In diesem Fall können die HTTP-Caches selbst eine plausible Verfallszeit bestimmen.
Wichtig: Solltest du für deine Website den Expires-Header einsetzen oder einsetzen wollen, musst du unbedingt berücksichtigen, dass der Browser erst nach Ablauf des Verfallsdatums eine neue Anfrage an den Webserver stellt. Deshalb ist es ratsam, für HTML-Dokumente kurze Verfallszeiten festzulegen. Bilder können hingegen ein Verfallsdatum erhalten, welches weit in der Zukunft liegt.
Validierung
Ist das Verfallsdatum einer lokal gespeicherten Kopie aus dem Browser-Cache überschritten, muss der Browser überprüfen, ob die vorhandene Kopie noch benutzt werden darf oder ob eine neue Version auf dem Webserver vorhanden ist. Dieser Vorgang wird Validierung genannt.
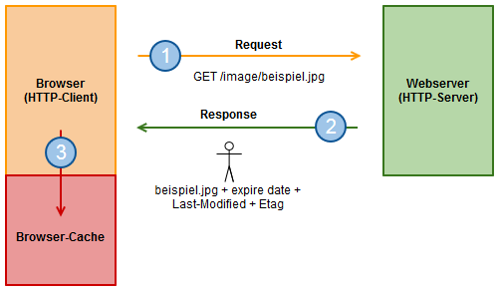
HTTP-Validierung: 1. Anforderung einer Ressource
Um eine solche Überprüfung durchzuführen, generiert der Webserver zusätzliche Informationen, die bei der ersten Anfrage der Ressource (1) an den Client übermittelt werden (2). Die zusätzlichen Informationen des Webservers, werden in den Feldern “Last-Modified” und “Etag” an den Client übertragen. Dieser legt die angeforderte Ressource und die Zusatzinformationen in seinem Browser-Cache ab (3).
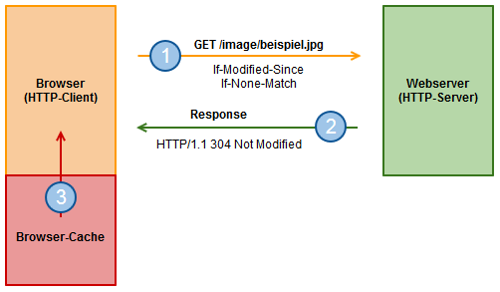
HTTP-Validierung: Überprüfung der Gültigkeit der lokalen Kopie
Ist das Expire-Date der Ressource überschritten und der Browser muss die Gültigkeit überprüfen, verwendet er die abgespeicherten Zusatzinformationen. Hierbei werden die Header-Einträge “If-Modified-Since” mit dem “Last-Modified”-Datum und “If-None-Match” mit dem “Etag”-Wert gesetzt und an den Server gesendet (1).
Im nächsten Schritt überprüft der Webserver die übermittelten Werte und sollten diese übereinstimmen, sendet er in seiner Antwort den Statuscode “304 Not Modified” (2). Dabei werden die Daten nicht erneut übertragen und der Client darf die lokale Kopie aus dem Browser-Cache verwenden (3). Wenn die übermittelten Werte des Clients nicht mit denen des Webservers übereinstimmen, werden die Daten erneut verschickt.
Wenn die lokale Kopie noch weiterhin gültig ist, werden durch diese Technik nur Steuerinformationen übertragen. Die viel umfangreicheren Daten brauchen nicht erneut übermittelt werden. Dadurch wird die Zahl der vollständigen Antworten reduziert und die Netzlast sinkt.
HTTP-Authentifizierung
Neben den Caching-Mechanismen, bietet das Hypertext Transfer Protocol auch die Möglichkeit einer Authentifizierung. Diese wird HTTP-Authentifizierung genannt und es lassen sich sehr leicht und ohne Programmierkenntnisse passwortgeschützte Bereiche innerhalb eines Internetauftritts einrichten. Denn nur wenn du die erforderlichen Benutzerdaten kennst, kannst du dich erfolgreich authentifizieren und dir die geschützten Inhalte anzeigen lassen.
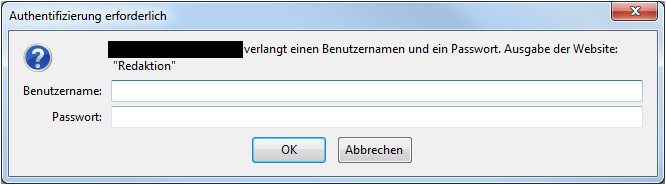
HTTP Authentifizierung
Technisch läuft das Verfahren so ab:
- Du forderst eine Ressource auf einem Webserver an.
- Der Webserver stellt fest, dass diese Ressource passwortgeschützt ist und die Eingabe eines Benutzernames und Passwort erforderlich ist.
- Der Webserver schickt deinem Browser eine Antwort mit dem Statuscode “401 Unauthorized” und dem Header-Feld “WWW-Authenticate”.
- Dein Browser überprüft, ob die Angaben zur Authentifizierung vorliegen oder zeigt dir das oben abgebildete Fenster an.
- Du trägst deine Benutzerdaten ein.
- Deine Benutzerdaten werden an den Webserver übertragen.
- Der Webserver überprüft die Daten auf Korrektheit.
- Sind die Daten korrekt, liefert er die angeforderte Ressource aus.
Es gibt mehrere Möglichkeiten zur Umsetzung der HTTP-Authentifizierung. Am häufigsten wird die “Basic Authentification” verwendet. Desweiteren gibt es noch die “Digest Access Authentication”.
Wenn du mehr über die HTTP-Authentifizierung und die beiden Verfahren zur Authentifizierung wissen möchtest, dann empfehle ich dir den dazugehörigen RFC oder das 11. Kapitel des Buches “Webdatenbank-Anwendungen mit PHP und MySQL”, welches als PDF frei abrufbar ist.
HTTP-Kompression
Damit nicht die vollständige Datenmenge einer Ressource übertragen werden muss, können HTTP-Server ihre Antworten komprimieren. Deshalb muss dein Browser bei seiner Anfrage an den Webserver, die Kompressionsverfahren mitteilen, die er unterstützt. Hierzu verwendet er das Header-Feld “Accept-Encoding”, welches du auch in Zeile 6 unserer Beispiel-Anfrage siehst.
Wenn der Server entsprechend konfiguriert wurde, komprimiert er seine Antwort mit dem vom Client unterstützen Verfahren und gibt im Header-Feld “Content-Encoding” das verwendete Kompressionsverfahren an.
Besonders bei Daten die aus reinem Text bestehen (HTML-Dokument, JavaScript-Datei oder CSS-Definitionen), werden so erhebliche Datenmengen bei der Übertragung eingespart. Textuelle Daten lassen sich nämlich sehr gut komprimieren, im Gegensatz zu bereits komprimierten Daten wie Bildern oder Audio-Dateien. Hier ist die Kompression eher nutzlos und wird deshalb eher selten eingesetzt.
Zusammenfassung
Das Hypertext Transfer Protocol ist ein Internetstandard, welcher zur Darstellung von Webseiten im Browser verwendet wird. Es handelt sich um ein zustandsloses Protokoll, mit persistenten Verbindungen und setzt direkt auf dem Transmission Control Protocol und dem Internet Protocol auf.
Neben der reinen Auslieferung der Webseiten im World Wide Web, hält es auch verschiedene Technik für ein effizientes Caching von Internetseiten bereit. Außerdem können mittels HTTP auch einfache geschützte Bereiche aufgebaut werden und das Protokoll kann seine Daten komprimiert versenden, um die Netzlast zu reduzieren.
Insgesamt ist es ein spannendes und wichtiges Protokoll. Dies merkst du nicht zuletzt an der länge dieses Artikels. Dabei bin ich an vielen Stellen noch nicht mal ins Detail gegangen. Dies werde ich aber in naher Zukunft nachholen und weitere Artikel, mit Bezug auf das Hypertext Transfer Protocol und die Caching-Mechanismen, veröffentlichen. Du darfst also gespannt sein. 🙂
Zum Schluss hätte ich noch eine Bitte an dich. Sollten dir fachliche Fehler im Artikel aufgefallen sein, dann wäre ich sehr froh, wenn du mir diese über die Kommentarfunktion mitteilst. Natürlich kannst du dort auch deine Meinung zum Protokoll hinterlassen.

Hallo,
das ist ein toller Artikel! Sehr gut beschrieben.
Aufgrund der Bitte für Rückmeldung denke ich, dass der Begriff “Requests” in folgendem Absatz durch “Response” ersetzt werden müsste, ist das korrekt?
“Zu den einzelnen Status-Meldungen kommen wir später noch einmal zurück, jetzt erst mal weiter mit der Auswertung des Requests.”
Begründung:
Der Absatz wird im Response-Bereich aufgeführt.
Grüße,
Hanspeter
Hallo Hanspeter,
vielen Dank für deinen Hinweis. Du hast natürlich Recht. Ich habe den Fehler auch gleich behoben.
Viele Grüße
Enrico
Toller Artikel!! Vielen Dank!