
Unsere Reise durch die weiten des Internets geht in die nächste Etappe.
Heute widme ich mich dem Transmission Control Protcol. Dieses wird auch kurz TCP genannt und stellt einen mindestens genauso wichtigen Baustein innerhalb der Infrastruktur des Internets dar, wie das Internet Protocol.
Deshalb gibt es auch viel zu lesen und zu lernen.
Ich hoffe du hast beim Lesen des Artikels genauso viel Spaß, wie ich beim Schreiben 🙂
Dieser Artikel ist Teil des 21.-teiligen Kurses “Das Internet“.
Einführung in das Transmission Control Protocol
Das Tansmission Control Protocol (kurz TCP) dient dem zuverlässigen und verbindungsorientierten Datentransport in Computernetzwerken. Es gehört zu den wichtigstens Standards im Internet und nutzt die Dienste des Internet Protocols (IP).
Verbindungsorientiert heißt im Falle von TCP nichts anderes, als das eine direkte und unmittelbare Verbindung zwischen zwei Endpunkten hergestellt wird.
Rufst du zum Beispiel eine Internetseite auf, wird zwischen deinem Computer und dem Webserver eine direkte Verbindung aufgebaut. Bei dieser Verbindung können Daten völlig unabhängig voneinander und in beide Richtungen übertragen werden. In der Kommunikationstechnik nennt man diese Art der Datenübermittlung auch Vollduplex.
Das Transmission Control Protocol wird hauptsächlich von Anwendungen genutzt, die Daten sicher übertragen müssen. So nutzt das World Wide Web das Protokoll fast ausschließlich als Transportmedium, aber auch der Versand von E-Mails und die Datenübertragung per FTP wird hierüber abgewickelt.
Doch wie kann ein sicherer und zuverlässiger Datentransport sicher gestellt werden und wie funktioniert das mit der direkten Verbindung genau?
Das sind die beiden zentralen Fragen, die es zu beantworten gilt. Doch zuerst müssen wir uns den TCP-Header anschauen!
Der TCP-Header
Der TCP-Header, bildet zusammen mit den Nutzdaten, dass TCP-Segment.
Die Größe des TCP-Segments hängt von der Größe des IP-Pakets ab. Im Artikel zum Internet Protocol, hatte ich ja bereits geschrieben, dass in den Nutzdaten des IP-Pakets die Protokollinformationen von TCP enthalten sind. Um also die Größe eines TCP-Segments zu errechnen, musst du einfach von den 1500 Byte des IP-Pakets, die Länge des IP-Headers (normalerweise 20 Byte) abziehen und erhältst die maximale Größe eines TCP Segments.
Kleiner Tipp, es sind 1480 Bytes 😉
In den Nutzdaten des TCP-Segments, befinden sich die zu übertragenden Daten. Bei diesen Daten handelt es sich wiederum um Informationen anderer Protokolle. Dies können u.a. Informationen des Hypertext Transfer Protocols oder des File Transfer Protocols sein. Das Stichwort hier lautet Datenkapselung. Solltest du nichts mit diesem Begriff anfangen können, dann lies dir am besten nochmal den Artikel ‘Wie funktioniert das Internet‘ durch. Dort habe ich das Verfahren der Datenkapselung anschaulich beschrieben.
Neben den Nutzdaten, ist der TCP-Header natürlich von entscheidender Bedeutung bei einem TCP-Segment. Dieser hat eine Größe von 20 Byte, wenn keine Optionen vorhanden sind. Er enthält Daten, die für die Kommunikation zwischen den beteiligten Endpunkten benötigt werden. Weiterhin sind auch Dateiformat-beschreibende Informationen im TCP-Header enthalten.
Der schematische Aufbau des TCP-Headers:
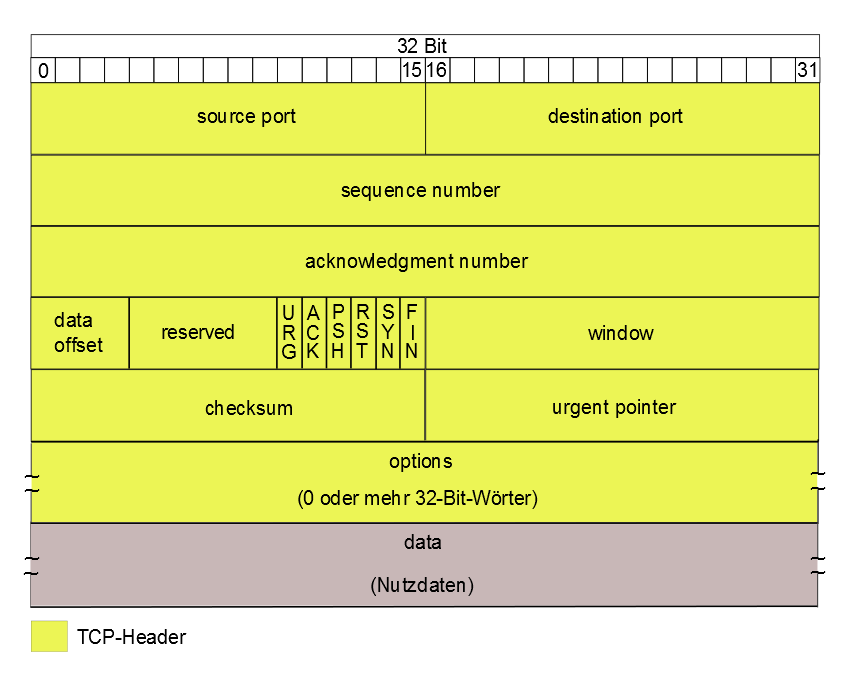
Schematische Darstellung des TCP-Headers
Appaloosa [GFDL oder CC-BY-SA-3.0], via Wikimedia Commons
Was bedeuten die einzelnen Felder des TCP-Headers?
Port (jeweils 2 Byte lang):
In diesen beiden Feldern, werden die Portnummern eingetragen, welche die Anwenderprozess auf Seiten der Endpunkte identifiziert.
Sequence Number (4 Byte):
Die Sequence Number gibt das erste Byte des TCP-Segments an oder enthält die Initial Sequence Number, wenn das SYN-Flag gesetzt ist. Nach der Datenübertragung, dient die Nummer zur Sortierung der TCP-Segmente. Diese können durch die Nutzung von IP in unterschiedlicher Reihenfolge beim Empfänger ankommen und müssen wieder korrekt zusammengefügt werden.
Acknowledgment Number (4 Byte):
Wenn das ACK-Flag des TCP-Headers gesetzt ist, enthält das Feld den Wert der nächsten Sequence Number, die vom Absender dieses Segment erwartet wird.
Data Offset (4 Bit):
Im Feld Data Offset wird die Länge des TCP-Headers angegeben. Mit dieser Information, kann der Beginn der Nutzdaten ermittelt werden.
Reserved (6 Bit):
Dieses Feld wird nicht genutzt und muss 0 sein.
Control-Flags (6 Bit):
Die folgenden Control-Flags können zwei mögliche Zustände annehmen. Entweder ist ein Flag gesetzt oder nicht gesetzt. Sie dienen zur Weiterverarbeitung der Daten und zum Auf- und Abbau der Kommunikation zwischen den beteiligten Endgeräten.
- URG
Dies ist das Urgent-Flag. Wenn es gesetzt ist, werden die Nutzdaten sofort von der Anwendung (die TCP nutzt) bearbeitet. Dazu unterbricht die Anwendung die Verarbeitung des aktuellen TCP-Segments und liest die Nutzdaten bis zu dem Byte aus, auf dass das Urgent-Pointer-Feld zeigt. - ACK
Über das Acknowledgment-Flag und der Acknowledgment Number wird der Empfang von TCP-Segmenten während der Datenübertragung bestätigt. Hierbei ist die Acknowledgment Number nur gültig, wenn auch das Acknowledgment-Flag gesetzt ist. - PSH
Werden Daten über das Transmission Control Protocol verschickt, gibt es auf Seiten des Senders und des Empfängers jeweils einen Puffer. Beim Sender werden die zu übertragenden Daten in einem Puffer abgelegt. Hier werden kleinere Übertragungen zu einer Größeren gebündelt und dann erst an den Empfänger verschickt. Das ist deutlich effizienter.
Sind die Daten beim Empfänger angekommen, landen Sie dort ebenfalls in einem Puffer. Auch hier werden die Daten gesammelt und gebündelt an die Applikation weitergereicht.
Wenn nun das Push-Flag gesetzt ist, dann werden beide Puffer übergangen. Hilfreich ist dies z.B. bei einer Telnet-Sitzung. Würde dein abgeschickter Befehl zuerst im Puffer landen, dann würde dieser mit einer starken Verzögerung ausgeführt werden. - RST
Wenn eine Verbindung abgebrochen werden soll, dann wird das Reset-Flag verwendet. Dies kann bei technischen Problemen oder unerwünschten Verbindungen geschehen. - SYN
Ist das SYN-Flag in einem TCP-Segment gesetzt, wird versucht eine Verbindung zu initiieren. Dabei dient es der Synchronisation der Sequence Number beim Verbindungsaufbau. - FIN
Über das FIN-Flag signalisiert der Sender dem Empfänger, das keine weiteren Daten folgen und die Verbindung freigegeben werden kann.
Window (2 Byte):
In diesem Feld wird die Anzahl der Bytes angegeben, die der Sender dieses TCP-Segments bereit ist zu empfangen.
Checksum (2 Byte):
Das Feld Checksum dient der Erkennung von Übertragungsfehlern. Sie wird aus dem TCP-Header, den Daten und einem sogenannten Pseudo-Header berechnet. Der Pseudo-Header setzt sich zusammen aus der Ziel-IP und der Quell-IP des IP-Pakets, der TCP-Protokollkennung und der Länge des TCP-Segments. Sollte auf der Seite des Empfängers ein Fehler bei der Berechnung dieser Prüfsumme auftreten, wird das Segment verworfen.
Urgent Pointer (2 Byte):
Der Wert dieses Feldes, zeigt auf die Position des ersten Datenbytes, welches nach den Urgent-Daten im Datenstrom folgt. Es ist nur gültig, wenn das Urgent-Flag gesetzt ist.
Options (0-40 Byte):
Ein TCP-Header kann Optionen enthalten, die in diesem Feld ihren Platz finden. Meist ist dieses Feld aber leer und deshalb hat der TCP-Header auch häufig eine länge von 20 Byte.
Ja. Das waren die Erklärungen zu den einzelnen Feldern des TCP-Headers. Wahnsinn wie viele das sind. Da stellt sich mir doch glatt die Frage, ob man wirklich alle unbedingt braucht? Und die Antwort ist: Ja!
Einen Großteil findest du bereits im nächsten Abschnitt ‘Verbindungsaufbau und -abbau’ wieder.
Der Verbindungsaufbau und -abbau
Beim Transmission Control Protocol wird eine direkte Verbindung zwischen zwei Endpunkten aufgebaut, bevor Daten übertragen werden können.
Wie oben schon geschrieben, kann es sich bei diesen Endpunkten z.B. um deinen Rechner handeln, der eine Website von einem Webserver abruft. In dem Fall besteht eine Ende-zu-Ende-Verbindung zwischen deinem Rechner und dem Webserver.
Eine solche Verbindung wird durch die folgenden vier Werte eindeutig identifiziert:
- Quell-IP-Adresse aus dem IP-Header
- Quell-Port aus dem TCP-Header
- Ziel-IP-Adresse aus dem IP-Header
- Ziel-Port aus dem TCP-Header
Bleiben wir bei dem Beispiel des Abrufs einer Website. Hier erzeugt der Webserver einen Endpunkt mit der Portnummer des Dienstes den er anbietet und seiner IP-Adresse.
Was eine IP-Adresse ist und wozu diese verwendet wird, dürfte dir aus dem letzten Abschnitt des Kurses begannt sein. Was ein Port ist, kannst du auf der Seite von Netzwelt nachlesen.
In unserem Fall, wird der Webserver die Portnummer 80 verwenden, da dieses der Standard-Port für HTTP ist und HTTP ist das Protokoll der Wahl, wenn es um die Auslieferung von Webseiten geht. Nach der Erzeugung des Endpunktes, wartet der Server auf mögliche Verbindungsanfragen.
Möchte dein Rechner jetzt den Dienst des Webservers in Anspruch nehmen und eine Website abrufen, erzeugt er seinerseits einen Endpunkt. Dieser besteht aus seiner IP-Adresse und einer eigenen freien Portnummer. Da dein Rechner ebenfalls den Standard-Port für HTTP kennt und die IP-Adresse des Webservers ermitteln kann, fügt er diese beiden Informationen zusammen und kann einen Verbindungsaufbau mit dem Server einleiten.
Wie dieser Aufbau bei TCP genau vonstattengeht, schauen wir uns jetzt an.
Der Verbindungsaufbau
Der Verbindungsaufbau zwischen deinem Rechner und dem Webserver geschieht in drei Schritten:
- Dein Rechner sendet ein TCP-Segment ohne Daten an den Webserver. In diesem Segment ist das SYN-Flag gesetzt und eine initiale Sequence Number (eine beliebige Zahl) wird übertragen.
- Der Webserver empfängt das Segment. Sollte der angesprochene Port auf dem Webserver geschlossen sein, kann keine Verbindung aufgebaut werden. Ist er jedoch geöffnet, bestätigt er den erhalt des TCP-Segments und stimmt dem Verbindungsaufbau zu.
Dazu antwortet der Server mit einem TCP-Segment, welches seine eigene initiale Sequence Number im entsprechendem Feld des TCP-Headers enthält. Bei dem Segment sind außerdem das SYN-Flag und das ACK-Flag gesetzt und die initiale Sequence Number von deinem Rechner wird um eins erhöht und im Acknowledgment Number Feld eingetragen. - Im letzten Schritt bestätigt dein Rechner den Erhalt des Segments vom Webserver. Hierzu erhöht er seine initiale Sequence Number um eins und trägt diese in das Feld Sequence Number ein. Zusätzlich wird die initiale Sequence Number des Webservers um eins erhöht und im Feld Acknowledgment Number eingetragen. Das entsprechende TCP-Segment wird dann mit dem gesetzten ACK-Flag an den Webserver verschickt und die Verbindung ist aufgebaut.
Den Verbindungsaufbau kannst du auch in der folgenden Abbildung nachvollziehen:
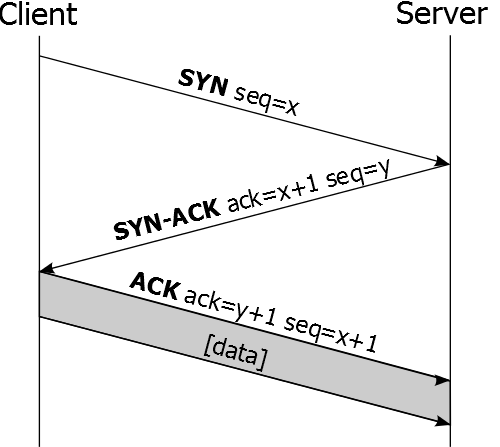
Der Verbindungsaufbau beim Transmission Control Protocol
By 300px-Tcp-handshake.png: ???derivative work: Snubcube (300px-Tcp-handshake.png) [CC-BY-SA-3.0 or GFDL], via Wikimedia Commons
Der Verbindungsabbau
Eine aufgebaute Verbindung sollte im besten Fall natürlich irgendwann auch wieder abgebaut werden. Da TCP im Vollduplex-Betrieb arbeitet, können beide Übertragungskanäle völlig unabhängig voneinander abgebaut werden. Außerdem kann der Verbindungsabbau von beiden Kommunikationspartnern eingeleitet werden, denn beide Kommunikationspartner sind hier gleichberechtigt.
Nehmen wir jetzt mal an, dass die von dir angeforderten Website vollständig an deinen Rechner übertragen worden ist. Nun möchte dein Rechner die Verbindung abbauen. Im einzelnen läuft der Verbindungsabbau dann wie folgt ab:
- Dein Rechner sendet ein FIN-Segment an den Server und signalisiert dadurch, dass er keine Daten mehr Senden möchte. In diesem Segment ist im TCP-Header die Sequence Number, der Source Port und der Destination Port angegeben. Außerdem ist das FIN-Flag gesetzt.
- Der Webserver bestätigt den Erhalt des FIN-Segments mit einem ACK-Segment. Bei diesem ACK-Segment ist das ACK-Flag gesetzt und die Sequence Number des Servers um eins erhöht. Diese Sequence Number wird in das Acknowledgment Number Feld eingetragen.
- Hat der Server alle noch anstehenden Daten an deinen Rechner übertragen, sendet er ebenfalls ein FIN-Segment mit einer entsprechenden Sequence Number. Hier sind die gleichen Felder und Flags gesetzt wie im ersten Schritt.
- Im letzten Schritt bestätigt dein Rechner das FIN-Segment des Webservers mit einem ACK-Segment. In diesem ist die Sequence Number des FIN-Segments des Servers um eins erhöht. Ansonsten sind die Informationen im TCP-Header identisch zu denen des zweiten Schritts und die Verbindung ist auf der Seite des Servers geschlossen.
Zum besseren Verständnis, kannst du den Ablauf auch nochmal in der nachfolgenden Grafik nachvollziehen:
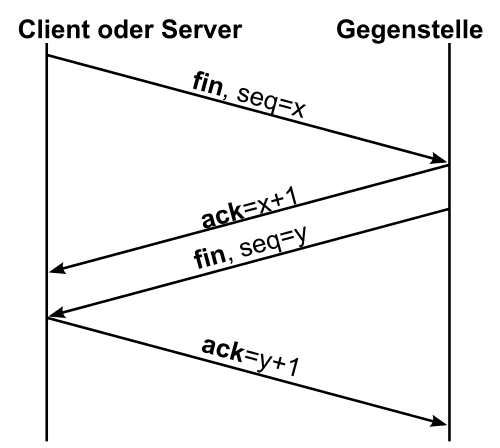
Der Verbindungsabbau bei TCP
By D235, SVG: Marlus_Gancher [GFDL], via Wikimedia Commons
Warum ist das so?
Da niemand garantieren kann, dass das letzte ACK-Segment auch wirklich bei der Gegenstelle ankommt und nicht unterwegs verloren geht, muss die Verbindung auf der Seite deines Rechners noch geöffnet bleiben. Dadurch bekommt die Gegenstelle die Chance, dass FIN-Segment erneut zu versenden.
Sollte die Verbindung bereits komplett abgebaut sein, ist es unklar, an wen dieses FIN-Segment gesendet werden soll und es kann zu erheblichen Storungen kommen.
Deshalb wartet dein Rechner. Doch er muss nicht ewig warten. Er muss nur solange warten, wie ein Segment maximal im Netz unterwegs sein kann und hierfür gibt es die maximale Segment Laufzeit (kurz MSL).
Die MSL wird in RFC 793 mit 2 Minuten angegeben. Da aber das letzte ACK-Segment und ein eventuell neu verschicktes FIN-Segment eine MSL besitzen, muss diese mal 2 genommen werden. Somit kann dein Rechner die TCP-Verbindung nach einer Wartezeit von 4 Minuten schließen.
Erst dann ist die Verbindung komplett abgebaut.
Die Datenübertragung
Bisher haben wir uns nur mit dem Auf- und Abbau der TCP-Verbindung auseinandergesetzt. Wenn du dich an unsere beiden Ausgangsfragen erinnerst, bin ich dir aber noch eine Antwort auf die Frage schuldig, wie TCP einen sicheren und zuverlässigen Datentransport gewährleistet.
Deshalb schauen wir uns jetzt an, wie die Datenübertragung bei TCP vonstatten geht.
Aufteilen der Anwendungsdaten
Bei der Übertragung von Daten über eine TCP-Verbindung, müssen die Daten in viele kleine Segmente aufgeteilt werden. Warum? Weil wir oben gelernt haben, dass ein TCP-Segment meist nur eine Größe von 1480 Byte besitzt. Davon gehen nochmal 20 Byte für den Header ab. Bleiben somit rund 1460 Byte für die Daten übrig.
1460 Byte sind 1,46 Kilobyte und das sind wiederum nur 0,00146 Megabyte.
Wenn man sich nur mal die Größe von Bildern anschaut, die in den meisten Webseiten verbaut sind, sind diese nicht selten mehrere 100 Kilobyte groß. Diese Menge an Daten kann natürlich nicht mit einem Segment übertragen werden, deshalb werden die Anwendungsdaten aufgeteilt.
Wie funktioniert das ganze jetzt?
Wir bleiben einfach mal bei dem Beispiel, dass du eine Webseite von einem Webserver abrufen möchtest.
Dann einigen sich dein Rechner und der Server während des Aufbaus einer Verbindung auf die maximale Segmentgröße (auch MSS genannt). Dazu nutzen die beiden das Feld Options des TCP-Headers. Größer als der hier vereinbarte Wert, darf kein Segment während der Datenübertragung sein.
Gehen wir nun davon aus, dass die Webseite ein 7 Kilobyte großes Bild beinhaltet und sich die beiden Kommunikationspartner auf eine maximale Segmentgröße von 1460 Byte geeinigt haben.
Bei der Erklärung des PSH-Flags hatte ich ja schon geschrieben, dass auf Seiten des Empfängers und des Senders jeweils ein Puffer existiert. Unser 7 Kilobyte großes Bild, wird im ersten Schritt in diesen Puffer auf seiten des Senders abgelegt.
Als nächstes teilt die TCP-Software unser Bild in mehrere Pakete auf. In unserem Beispiel sind es 5 Segmente. Danach erhält jedes Segment einen Header und die so vorbereiteten Segmente werden nacheinander abgeschickt.
Schematisch sieht das Ganze ungefähr so aus:
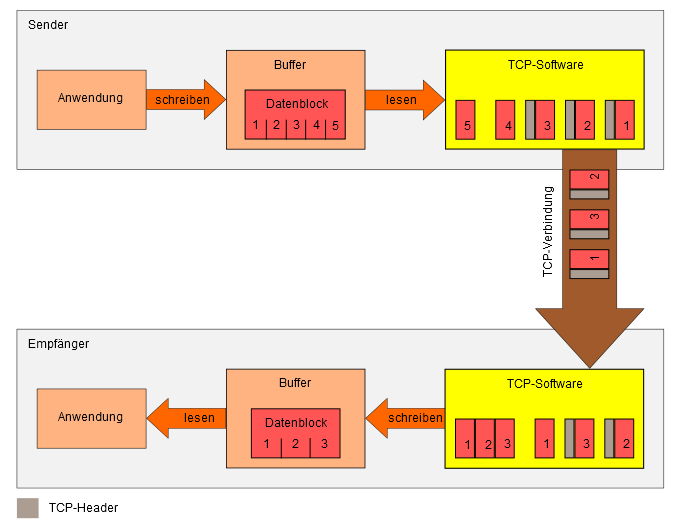
Aufteilung der Daten bei TCP
I, Appaloosa [GFDL oder CC-BY-SA-3.0], via Wikimedia Commons
Beim Internet Protocol war es ja so, dass die IP-Pakete nicht immer den gleichen Weg zum Empfänger nehmen und manche Pakete dadurch länger für den Weg brauchen als andere. Dadurch kann es schon mal vorkommen, dass das zweite Paket vom dritten überholt wird.
Aus diesem Grund ist jedes einzelne TCP-Segment nummeriert. Anhand dieser Nummerierung kann der Empfänger die Segmente wieder in die richtige Reihenfolge bringen und unser Bild korrekt zusammenfügen.
Dafür wird die Sequence Number des TCP-Headers verwendet. Hierzu aber später mehr.
Nun kann es aber auch sein, dass einzelne IP-Paket auf dem Weg verloren gehen. Deshalb muss der Empfänger den Erhalt eines jeden TCP-Segments bestätigen. Ist ein Paket nicht angekommen, verschickt der Sender dieses erneut.
Durch diesen Prozess wird eine sichere Übertragung unserer Daten sichergestellt. Damit du diesen wichtigen Prozess noch besser verstehst, folgt jetzt eine Beispielübertragung.
Eine Beispielübertragung
Ist die Verbindung zwischen deinem Rechner und dem Webserver aufgebaut, die maximale Segmentgröße vereinbart und die TCP-Segmente aufgeteilt und vorbereitet, kann die Übertragung unseres 7 Kilobyte großen Bildes beginnen.
Der Webserver beginnt die Übertragung mit dem Verschicken des ersten Segments. Dieses besitzt eine Sequence Number und in den Nutzdaten sind die ersten 1460 Byte des Bildes enthalten. In unserm Beispiel hat das Segment die Sequence Number 1.
Dein Rechner erhält dieses Segment. Er antwortet seinerseits mit einem Segment ohne Daten, bei dem im Acknowledgment Number Feld die 1461 eingetragen ist. Damit fordert er beim Sender das zweite TCP-Segment, ab dem Byte mit der Nummer 1461 unseres Bildes, an.
Der Webserver reagiert darauf und schickt das zweite Segment mit einer Sequence Number von 1461 an deinen Rechner. Dein Rechner bestätigt den Empfang wieder mit der Acknowledgment Number von 2921.
So geht das Spiel weiter, bis alle TCP-Segmente bei dir angekommen sind.

Eine Beispielübertragung
Appaloosa aus der deutschsprachigen Wikipedia [GFDL oder CC-BY-SA-3.0], via Wikimedia Commons
Da dies nicht besonders effizient ist, können auch mehrere Segmente nacheinander verschickt werden und der Empfänger der Segmente, kann diese mit nur einem Acknowledgment-Segment bestätigen.
Hierbei ist es aber wichtig, dass die Segmente zusammenhängend bei dir ankommen und keine unterwegs verloren gehen. Ist dies der Fall und dein Rechner empfängt die TCP-Segmente 1-5, dann braucht er nur das letzte zu bestätigen. Diese Bestätigung hätte dann im Feld Acknowledgement Number die 7301 eingetragen.
Geht jedoch ein Segment auf dem Weg zwischen Sender und Empfänger verloren, kann der Empfänger nur die bestätigen, die zusammenhängend bei ihm angekommen sind.
Sagen wir mal, dass das 3. Segment unseres Bildes verloren gegangen ist. Bei unserem Rechner sind aber die Segmente 1-2 und 4-5 angekommen. In diesem Fall kann dein Rechner nur die Segmente 1-2 bestätigen, 4-5 leider noch nicht.
Da der Webserver keine Bestätigung für das 3. Segment bekommt, läuft der sogenannte Retransmission Timer ab. Nach Ablauf des Timers, verschickt er das Segment erneut und wenn dieses jetzt bei dir ankommt, dann bestätigt dein Rechner gleich alle 5 TCP-Segmente und die Übertragung ist beendet.
Vielleicht erahnst du es schon. Der Retransmission Timer spielt hierbei eine wichtige Rolle. Dieser wird für jedes Segment gestartet, die der Sender auf die Reise schickt und ist damit ein wichtiger Baustein zum Erkennen und Beheben von Datenverlusten während der Übertragung.
Erkennen und Beheben von Datenverlusten
TCP ist ein zuverlässiges Protokoll zur Datenübertragung und stellt gleichzeitig sicher, dass alle gesendeten Daten beim Empfänger ankommen. Hierzu wird das Verfahren der positiven Acknowledgments genutzt. Also das der Erhalt der angekommen Daten vom Empfänger bestätigt werden muss.
Doch wie gerade schon geschrieben, können Datenpakete oder sogar die Bestätigungen verloren gehen.
Wie geht TCP damit um?
Damit der Verlust von Segmenten erkannt und behoben werden kann, benutzt TCP beim Senden der Daten, den sogenannten Retransmission Timeout (RTO). Ist dieser Timer abgelaufen, bevor eine Bestätigung beim Sender eintrifft, wird das Segement einfach nochmal verschickt. Dieser Vorgang wiederholt sich solange, bis eine positive Bestätigung beim Sender eingetroffen ist.
Und wie lange läuft dieser Timer, bevor das Segment erneut verschickt wird?
Das ist eine sehr gute Frage und eine feste Länge gibt es hier gar nicht. Das muss aber auch so sein, da die Bestätigungen mal eine schnellere und mal eine langsamere Laufzeit besitzen. Dies hängt hauptsächlich von der geographischen Distanz ab, die zwischen dem Sender und dem Empfänger zurückgelegt werden muss.
Kommen die Bestätigungen schnell beim Sender an, kann der Timer niedriger gewählt und damit die Leitung besser ausgelastet werden. Dauert es länger, muss der Timer natürlich größer gewählt werden.
Zur Bestimmung der Länge des Timers, kommt eine der wichtigstens Eigenschaften von TCP zum tragen. Das Protokoll passt den Retransmission Timeout nämlich dynamisch den unterschiedlichen Geschwindigkeiten der Übertragungsleitungen an. Zur Bestimmung der optimalen Laufzeit des Timers, wurden im Laufe der Zeit, verschiedene Algorithmen ausprobiert. Den aktuellen Stand, kannst du in RFC 2988 nachlesen.
Die Zusammenfassung
Wenn du diese Zeilen hier noch lesen solltest, dann muss ich dir ein großes Kompliment aussprechen!
Es war nämlich nicht gerade einfacher Stoff, den ich dir in diesem Artikel versucht habe zu vermitteln und ganz kurz war der Artikel auch nicht. Aus diesem Grund, hast du dir auch eine Zusammenfassung verdient 🙂
Werden Daten mittels TCP übertragen, wird eine direkte Verbindung zwischen zwei Endpunkten aufgebaut. Der Verbindungsaufbau wird auch “Drei-Wege-Handschlag” genannt, da zuerst eine Seite ein SYN-Segment sendet, welches vom Empfänger mit einem ACK-Segment bestätigt wird. Nachdem die erste Seite ein weiteres ACK-Segement gesendet hat, ist die Verbindung hergestellt und es können Daten übertragen werden.
Bei der Übertragung werden die Daten in einzelne Segemente aufgeteilt, mit einem TCP-Header versehen und nacheinander an den Empfänger verschickt. Um zu Erkennen, ob alle Pakete beim Empfänger angekommen sind, muss jedes Segement bestätigt werden. Geht ein Paket verloren, verschickt der Sender das Paket erneut. Hierzu nutzt er den sogenannten Retransmission Timeout.
Sind alle Daten übertragen, wird die Verbindung wieder abgebaut. Hierzu schickt eine Seite (egal ob Sender oder Empfänger) ein FIN-Segment. Der Empfänger des FIN-Segments bestätigt dieses mit einem ACK-Segment. Er kann aber weiterhin noch Daten übertragen.
Sind alle Daten vom Empfänger des FIN-Segments verschickt worden, verschickt dieser seinerseits ein FIN-Segment, welches wieder durch ein ACK-Segement bestätigt wird. Die Verbindung ist damit auf der Seite des Senders des zweiten FIN-Segments abgebaut. Die Gegenseite geht in den Time-Wait-Zustand über. Dieser Zustand ist notwendig, falls das letzte ACK-Segment verloren geht.
Da bleibt mir jetzt eigentlich nur noch zu sagen, dass ich in diesem Artikel längst nicht auf alle wichtigen Eigenschaften des Transmission Transfer Protocols eingehen konnte. Das hätte einfach den Rahmen gesprengt.
Wenn du dein Wissen zu TCP noch weiter vertiefen möchtest, dann kann ich dir nur empfehlen, dich z.B. mit dem Schiebefenster-Mechanismus oder der Überlastkontrolle zu beschäftigen.
Für mich ist hier Schluß und ich würde mich über Kommentare oder Verbesserungsvorschläge von dir sehr freuen.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
[…] 1460 Byte sind 1,46 Kilobyte und das sind wiederum nur 0,00146 Megabyte. […]
Das ist nicht ganz korrekt. Bei Umrechnung von Byte, Kilobyte, Megabyte usw. beträgt der Faktor jeweils 1024 und nicht 1000.
Das heißt also: 1460 Byte sind 1460 / 1024 ~ 1,426 KByte bzw. ~ 0,00139 MByte usw.
Ansonsten guter Beitrag und vor allem verständlich geschrieben. Vielen Dank.
Hallo Jürgen,
vielen Dank für den Hinweis. Du hast natürlich Recht und ich habe das Beispiel angepasst. Ich weiß nicht was mich da geritten hat, aber ich sollte wohl zukünftig nicht blind dem Umrechnungsservice von Google vertrauen 🙁
Viele Grüße
Enrico
Du verwechselst Kilo mit Kibybite.
Kilo, Mega usw wurde zum allgemeineren Verständnis mit einem Dezimalen Faktor (1000) gebildet.
In der IT jedoch verwendet man das Binäre System mit Binären Faktor (1024).
Somit sind 1000 Byte ein Kilobyte. 1024 sind ein Kibibyte
Hallo Kevin,
Hallo Jürgen,
ich habe mich jetzt nochmal ausgiebig mit dem Thema beschäftigt und kehre zu meiner ursprünglichen Umrechnung zurück.
Quelle um den Sachverhalt besser zu verstehen:
http://ss64.com/convert.html
Vielen Dank für eure Hinweise 🙂
Hallo Enrico,
ich hoffe, dass du die Serie weiterführst, da sie wirklich interessant und gut geschrieben ist.
Bei dem Teil am Anfang, wo du verbindungsorientiert erwähnst, wäre es vielleicht noch von Vorteil zu erwähnen, dass bei einer verbindungsorientierten Datenübertragung und durchgehender Austausch zwischen zwei (oder mehreren) Zielsystemen vonstatten läuft. Ergo => kommt ein Packet beim Empfänger nicht ganz oder gar komplett an, wird es erneut gesendet.
Viele Grüße!
Hi Ken,
vielen Dank für deine netten Worte. Die Serie werde ich ganz sicher irgendwann fortsetzen. Im Moment fehlt mir aber leider die Zeit…
Über deinen Vorschlag werde ich mir mal ein paar Gedanken machen und den Artikel ggf. anpassen.
Viele Grüße
Enrico
du rettest mich in der informatik-stunde… DANKE!!
Das freut mich 🙂
Hey!
Ich schreibe morgen meine Prüfung in MIS und hatte gar nichts von dem TCP und IP verstanden. Dank dir verstehe ich viel mehr und fühle mich besser vorbereitet, danke dir! Super geschrieben, sogar mit bisschen Humor 🙂
Grüsse,
Eileen
Hi Eileen,
es freut mich sehr, dass dir meine Erklärungen zum Transmission Control Protokoll gefallen und auch weitergeholfen haben. Ich drücke dir für deine heutige Prüfung die Daumen 🙂
Viele Grüße
Enrico
Hallo und vielen Dank für die Beiträge!
Sehr verständlich, auch wenn mir das ein oder andere noch etwas unklar ist.
Irgendwo war ein Schreibfehler! Ich habe ihn allerdings beim Überfliegen nicht mehr gefunden 🙂
Viele Grüße