
Im 8. Teil des Online-Kurses zum Netz der Netze, widme ich mich heute dem User Datagramm Protocol. Es wird auch kurz UDP genannt und kommt häufig bei der Übertragung von Sprach- und Videomaterial im Internet zum Einsatz.
Bei diesem Protocol können Daten vertauscht werden, doppelt ankommen oder sogar verloren gehen. Im Gegensatz zu TCP findet hier also keine Überprüfung statt, ob alle Daten korrekt beim Empfänger angekommen sind und deshalb sprechen wir auch von einem ungesicherten und verbindungslosen Protokoll.
Warum sich UDP trotzdem einer starken Beliebtheit erfreut und von vielen Anwendung zur Übertragung von Daten im Internet eingesetzt, erfährst du wenn du weiterliest.
Dieser Artikel ist Teil des 21.-teiligen Kurses “Das Internet“.
Einführung in das User Datagram Protocol
Das User Datagram Protocol (kurz UDP) ist ein minimales Netzwerkprotokoll, welches Anwendungen erlaubt, Daten über das Internet auszutauschen. Genauso wie TCP, ist das User Datagram Protocol auf der Transportschicht des OSI-Modells zu finden und nutzt die Dienste des IP-Protocols.
Auch bei UDP werden die zu übertragenden Daten in viele kleine Pakete aufgeteilt. Diese Pakete werden Datagramme genannt. Es kann vorkommen, dass Datagramme auf dem Weg zum Empfänger verloren gehen, vertauscht werden oder doppelt ankommen. Aus diesem Grund spricht man bei UDP von einem ungesichertem Protokoll.
Eine Anwendung die UDP nutzt, muss deshalb entsprechende Korrektur- oder Sicherungsmaßnahmen selbst vornehmen können oder aber unempfindlich gegenüber verlorengegangenen oder vertauschten Paketen sein.
Anders als beim Transmission Control Protocol, wird beim User Datagramm Protocol, keine feste Verbindung zwischen den Kommunikationspartner aufgebaut. Deshalb ist es nicht nur ein ungesichertes, sondern auch ein verbindungsloses Protokoll.
Das hat den großen Vorteil, dass schneller mit dem Datenaustausch begonnen werden kann. So setzen hauptsächlich Anwendung auf UDP, bei denen sich die Kommunikation auf einen einfachen Anfrage-Antwort-Mechanismus beschränken lässt. Eine typische Anwendung wäre z.B. das Time-Protokoll, welches die Uhrzeit eines anderen Rechners abfragt. Aber auch das DNS (Domain Name System) ist ein sehr bekanntes Protokoll, welches die Dienste nutzt.
Ein weiterer Vorteil liegt darin, dass UDP ein ungesichertes Protokoll ist. Dadurch kommt es nämlich nur zu geringen Übertragungsverzögerungsschwankungen.
Übertragungsverzögerungsschwankungen? Was ist das denn?
Gute Frage!
Im letzten Teil dieses Online-Kurses, hatte ich geschrieben, dass verlorengegangene Segmente bei TCP automatisch neu angefordert werden. Das braucht Zeit und es kommt zu Übertragungsverzögerungen. Da die Daten nicht alle gleich schnell über die Infrastruktur des Internets übertragen werden, ist die Laufzeit der Segmente zusätzlich gewissen Schwankungen unterworfen. Diese beiden, doch eher negativen Eigenschaften, werden zu den Übertragungsverzögerungsschwankungen.
Beim User Datagram Protocol sind diese jedoch nur gering, weshalb Multimediaanwendungen das Protokoll einsetzen. Hier ist es nämlich nicht entscheidend, ob alle Datagramme beim Empfänger ankommen. Gehen unterwegs einige Pakete verloren, vermindert dies lediglich die Qualität der Sprachausgabe oder des Videos. Würden Videos oder Sprache per TCP übertragen, könnte es zu Aussetzern kommen, was viel schlimmer wäre.
Die Funktionsweise
Damit die per UDP übertragenen Daten der richtigen Anwendung auf dem Zielrechner zugeordnet werden können, werden sogenannte Ports verwendet. Dazu wird die Portnummer der Anwendung im UDP-Header mitgesendet.
Dies dürftest du schon von TCP kennen.
Bei den Portnummern unterscheiden wir zwischen:
- Wohlbekannten Portnummern – Diese gehen von 0 bis 1023 und können nur von Systemprozessen oder priviligierten Benutzern benutzt werden. FTP nutzt z.B. den Port 21 oder HTTP den Port 80.
- Registrierten Portnummern – Sie haben eine Spanne von 1024 – 49151 und werden typischerweise Server-Programmen zugeordnet.
- Dynamischen Portnummern – Diese Ports können frei genutzt werden und liegen zwischen 49152 bis 65535. Benutzt werden diese Ports von Client-Programmen wie einem FTP-Programm oder den Internet-Browsern.
Die registrierten und dynamischen Portnummern werden nur solange benutzt, wie ein Client-Programm aktiv ist.
Wenn zwei Kommunikationspartner im Internet miteinander kommunizieren, müssen neben den beiden IP-Adressen auch beide Ports definiert sein. Dies sind nämlich die erforderlichen Informationen bei einer Kommunikation im Internet und sind zwingend notwendig, damit die Daten korrekt beim Anwendungsprogramm des Empfänger ankommen.
Das UDP-Datagramm
Wie Eingangs schon erwähnt, werden bei UDP die Daten in Datagrammen übertragen. Neben den eigentlichen Daten werden bei einer Übertragung mittels UDP, weitere Informationen gesendet, die sich im sogenannten UDP-Header befinden.
Diesen Header schauen wir uns jetzt genauer an. Außerdem erkläre ich dir, wozu der Pseudo-Header bei UDP genutzt wird. Danach gehe ich noch auf die maximale Datagramm-Größe, bevor der Artikel auch schon mit dem Fazit beendet wird.
Der UDP-Header
Im Gegensatz zum IP- oder dem TCP-Header, ist der UDP-Header vergleichsweise klein. Er ist nur 8 Byte lang und besteht aus den folgenden 4 Feldern:
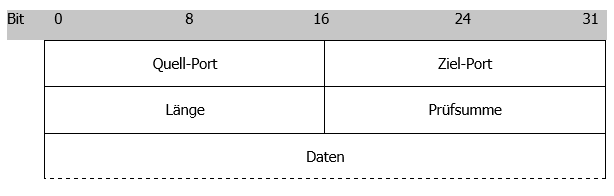
Der UDP-Header mit Nutzdaten
Diese Felder sind alle 16-Bit lang und bedeuten:
Ports:
Über den Quell- und Ziel-Port werden die Anwenderprozesse identifiziert, die auf Sender- und Empfängerseite an der Kommunikation beteiligt sind. Da es sich bei UDP um ein verbindungsloses Protokoll handelt, ist der Quell-Port optional und könnte auch den Wert 0 annehmen.
Länge:
In diesem Feld wird die Länge des UDP-Headers und der Daten angegeben. Die Angabe ist in Byte.
Prüfsumme:
Die Prüfsumme ist optional. Sie wird aus dem sogenannten Pseudo-Header berechnet. Dieser besteht aus dem UDP- und Teilen des IP-Headers. Die Prüfsumme sollte immer berechnet werden, auch wenn einige Anwendung dies nicht tun. Mehr dazu im nächsten Abschnitt unter “Der Pseudo-Header”.
Daten:
Das Feld Daten, enthält die eigentlichen Nutzdaten, die mit UDP übertragen werden. Theoretisch kann das Feld auch leer sein, was aber in der Regel nicht vorkommt.
Der Pseudo-Header
Für die Übertragung des UDP-Datagramms ist das Internet Protokoll vorgesehen. Hierzu wird das Datagramm in die Nutzdaten des IP-Pakets eingefügt. Das fertige IP-Paket sieht dann so aus:

UDP-Datagramm gekapselt in einem IP-Packet
By MartinThoma (Own work) [CC BY 3.0], via Wikimedia Commons
Diese Fehlererkennung ist aber lediglich dazu gedacht, Manipulationen an den übertragenen Daten zu erkennen. Sie dient nicht dazu, fehlerhafte Datagramme erneut beim Sender anzufordern. Sollte ein Datagramm mit einer fehlerhaften Prüfsumme beim Empfänger ankommen, wird es ohne jegliche Benachrichtigung verworfen.
Fehlt noch etwas? Achja. Hier die Teile aus denen sich der Pseudo-Header zusammensetzt:

Der UDP-Pseudo-Header
Die maximale Datagramm-Größe
Das UDP-Datagramm kann eine maximale Größe von 65535 Bytes annehmen. Davon sind 8 Byte für den Header reserviert. Bleiben theoretische 65527 Bytes für die Daten übrig.
Jetzt wissen wir aber, dass UDP die Dienste des IP-Protocols in Anspruch nimmt und wenn du diesen Kurs aufmerksam verfolgt hast, dann weißt du auch, dass es zu einer Datenkapselung kommt. Deshalb müssen wir von den theoretischen 65527 Bytes noch mal die Länge des IP-Headers abziehen.
In einem UDP-Datagramm können also maximal 65507 Bytes gesendet werden.
Fazit
UDP ist ein ungesichertes und verbindungsloses Netzwerkprotokoll, bei dem Daten unterwegs verloren gehen, vertauscht werden oder doppelt ankommen können. Genau wie das Transmission Control Protocol, nutzt UDP die Dienste des Internet Protocols.
Hauptsächlich wird es von Multimediaanwendungen zur Übertragung von Sprache oder Videomaterial genutzt. Aber auch Dienste wie das DNS nutzen die Dienste vom User Datagram Protocol.
Der UDP-Header besteht aus 4 Feldern, welche unter anderem Angabe für den Quell- und Ziel-Port enthalten. Diese Port-Angaben sind zwingend notwendig, damit die Anwendungen auf der Sender- und der Empfängerseite eindeutig zugeordnet werden können.
Zur Erkennung von Manipulationen an den verschickten Datagrammen, dient der sogenannte Pseudo-Header. Dieser besteht aus Teilen des IP-Headers und dem gesamten UDP-Header.

{kind=link}
Wie werden die Daten von z.B. Integer nach Bytes und beim Empfänger zurück in den Ausgangszustand gewandelt.
Hallo Wilhelm,
grob vereinfacht dargestellt, kannst du dir das so vorstellen:
Der Datentyp Integer besteht, abhängig von der Programmiersprache und der Wortbreite der CPU, aus 8, 16, 32, 64 oder 128 Bit. Der Einfachheit halber, gehen wir mal von 8 Bit aus und berücksichtigen auch nicht das Vorzeichen.
Speicherst du jetzt z.B. die Zahl 16 als Integer-Variable ab, entspricht diese der Bitfolge 00010000. Diese Bitfolge wird in den Datenbereich des genutzten Prokotolls eingefügt und übertragen. Der Empfänger interpretiert diese Bitfolge wieder als die Zahl 16 und verarbeitet diese.
Ich hoffe das hilft dir einigermaßen weiter.
Viele Grüße
Enrico
Du schreibst im ersten Abschnitt “IP-Protokoll”. Das P heißt doch schon Protokoll, sodass es redundant ist oder irre ich hier.
Ulrike
Hallo Ulrike,
im Prinzip hast du natürlich Recht. Korrekterweise würde “IP-Protokoll” ausgeschrieben “Internet Protocol Protokoll” heißen. Da diese Schreibweise aber selbst in der Fachliteratur und in wissenschaftlichen Arbeiten zufinden ist, benutze ich diese ebenfalls.
Viele Grüße und vielen Dank für deinen Hinweis
Enrico